Cassandra 的数据模型与我们通常在 RDBMS 中看到的数据模型有很大的不同。本章介绍了 Cassandra 如何存储数据的概述。
Cassandra 数据库分布在几个一起操作的机器上。最外层容器被称为群集。对于故障处理,每个节点包含一个副本,如果发生故障,副本将复制。Cassandra 按照环形格式将节点排列在集群中,并为它们分配数据。
键空间是 Cassandra 中数据的最外层容器。Cassandra 中的一个键空间的基本属性是 -
复制因子 - 它是集群中将接收相同数据副本的计算机数。
副本放置策略 - 它只是把副本放在介质中的策略。我们有简单策略(机架感知策略),旧网络拓扑策略(机架感知策略)和网络拓扑策略(数据中心共享策略)等策略。
列族 - 键空间是一个或多个列族的列表的容器。列族又是一个行集合的容器。每行包含有序列。列族表示数据的结构。每个键空间至少有一个,通常是许多列族。
创建键空间的语法如下 -
CREATE KEYSPACE Keyspace name
WITH replication = {'class': 'SimpleStrategy', 'replication_factor' : 3};
下图显示了键空间的示意图。

列族是有序收集行的容器。每一行又是一个有序的列集合。下表列出了区分列系列和关系数据库表的要点。
| 关系表 | Cassandra 列族 |
|---|---|
关系模型中的模式是固定的。 一旦为表定义了某些列,在插入数据时,在每一行中,所有列必须至少填充一个空值。 | 在 Cassandra 中,虽然定义了列族,但列不是。 您可以随时向任何列族自由添加任何列。 |
| 关系表只定义列,用户用值填充表。 | 在 Cassandra 中,表包含列,或者可以定义为超级列族。 |
Cassandra 列族具有以下属性 -
keys_cached - 它表示每个 SSTable 保持缓存的位置数。
rows_cached - 它表示其整个内容将在内存中缓存的行数。
preload_row_cache -它指定是否要预先填充行缓存。
注 - 与不是固定列族的模式的关系表不同,Cassandra 不强制单个行拥有所有列。
下图显示了 Cassandra 列族的示例。
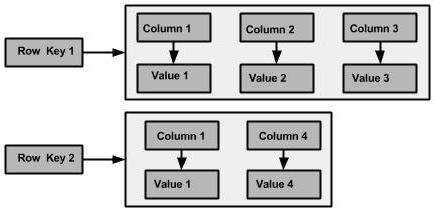

超级列是一个特殊列,因此,它也是一个键值对。但是超级列存储了子列的地图。
通常列族被存储在磁盘上的单个文件中。因此,为了优化性能,重要的是保持您可能在同一列族中一起查询的列,并且超级列在此可以有所帮助。下面是超级列的结构。

下表列出了区分 Cassandra 的数据模型和 RDBMS 的数据模型的要点。
| RDBMS | Cassandra |
|---|---|
| RDBMS 处理结构化数据。 | Cassandra 处理非结构化数据。 |
| 它具有固定的模式。 | Cassandra 具有灵活的架构。 |
| 在 RDBMS 中,表是一个数组的数组。 (ROW x COLUMN) | 在 Cassandra 中,表是“嵌套的键值对”的列表。 (ROW x COLUMN 键 x COLUMN 值) |
| 数据库是包含与应用程序对应的数据的最外层容器。 | Keyspace 是包含与应用程序对应的数据的最外层容器。 |
| 表是数据库的实体。 | 表或列族是键空间的实体。 |
| Row 是 RDBMS 中的单个记录。 | Row 是 Cassandra 中的一个复制单元。 |
| 列表示关系的属性。 | Column 是 Cassandra 中的存储单元。 |
| RDBMS 支持外键的概念,连接。 | 关系是使用集合表示。 |